File类
File类对应于一个目录或者一个文件,注意在使用文件的时候,比如通过流往文件中写入内容,该文件可以不存在,但是其父目录必须是有效的。
JAVA IO类层次
Java的IO类有可以分为两大类,一类是面向字节的流,一类是面向字符的流。每个类又分为输入流和输出流。其下面又分为定义数据来源或去除的流,以及改变流行为的装饰流。注意,输出流和输出流都是以内存为对象的,流入内存的是输入流,从内存流出的是输出流。
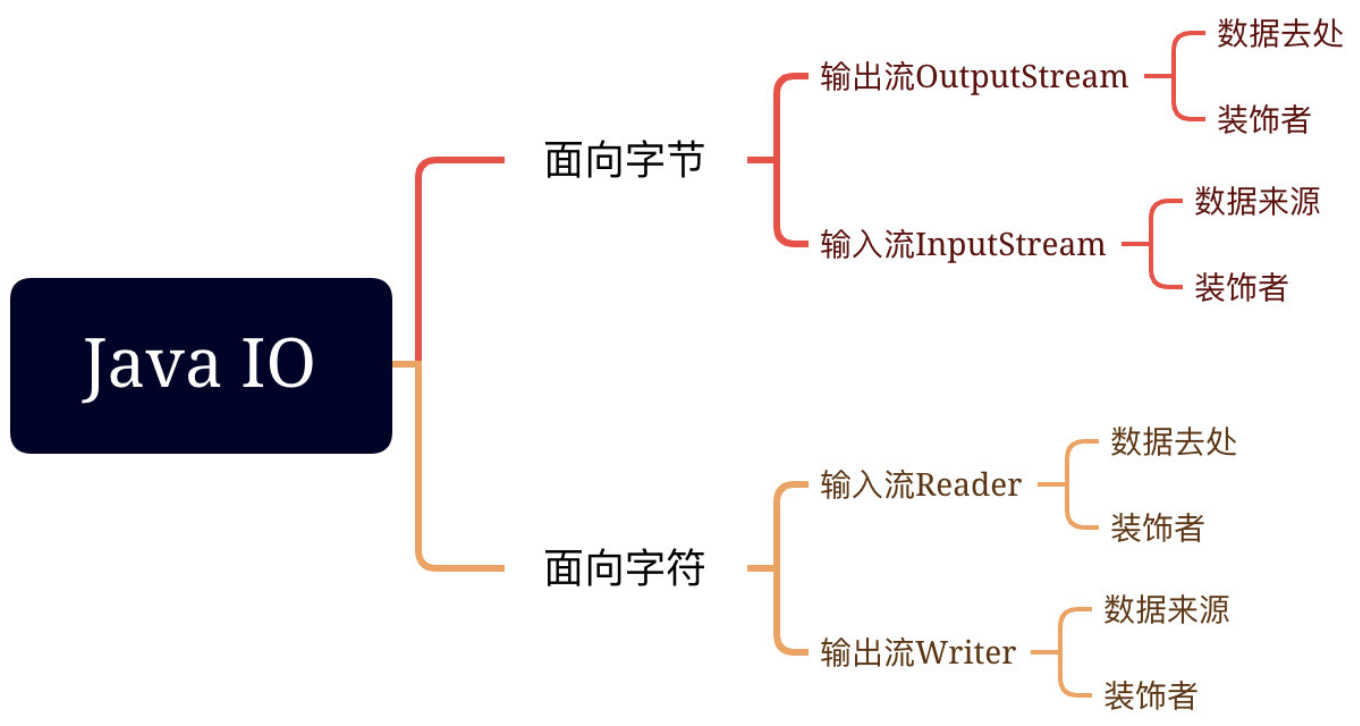
具体类如下所示。
面向字节
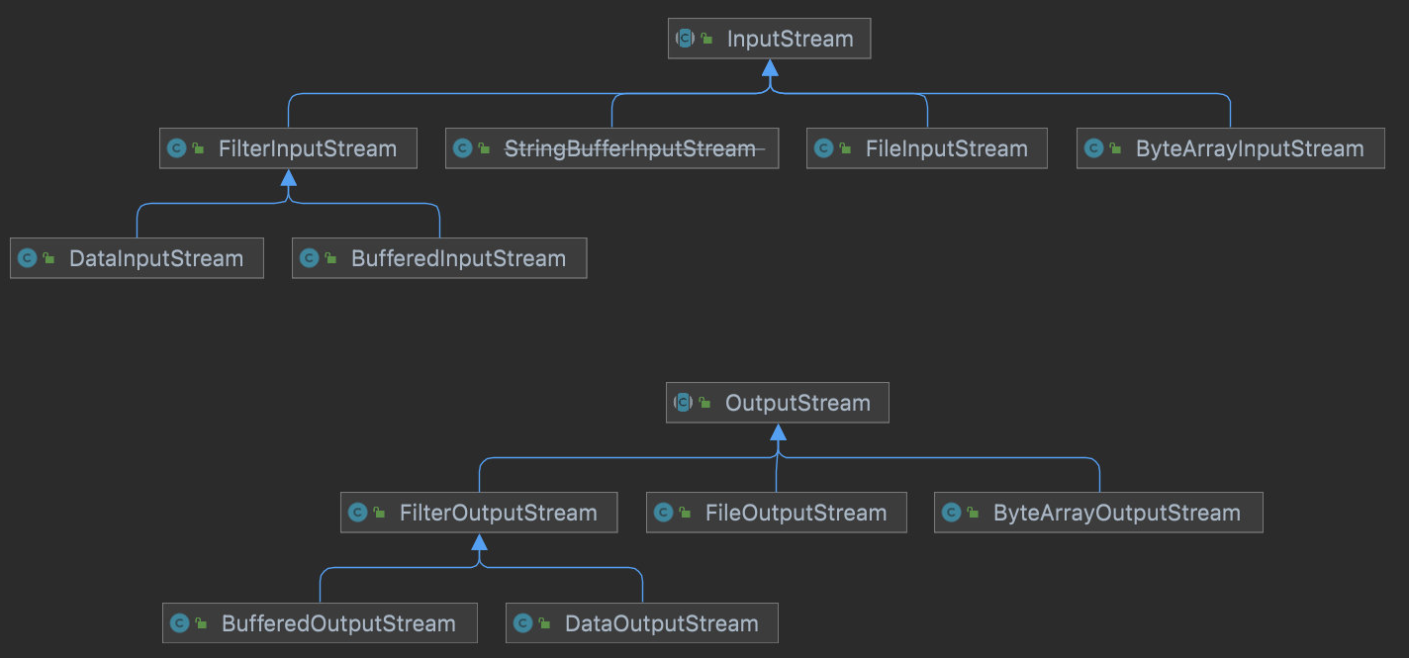
其中FileXXXStream,ByteArrayXXXStream都是用于指明数据的来源或去处,而FilterInputStream的子类则是通过装饰器设计模式来修改流的一些行为。
面向字符
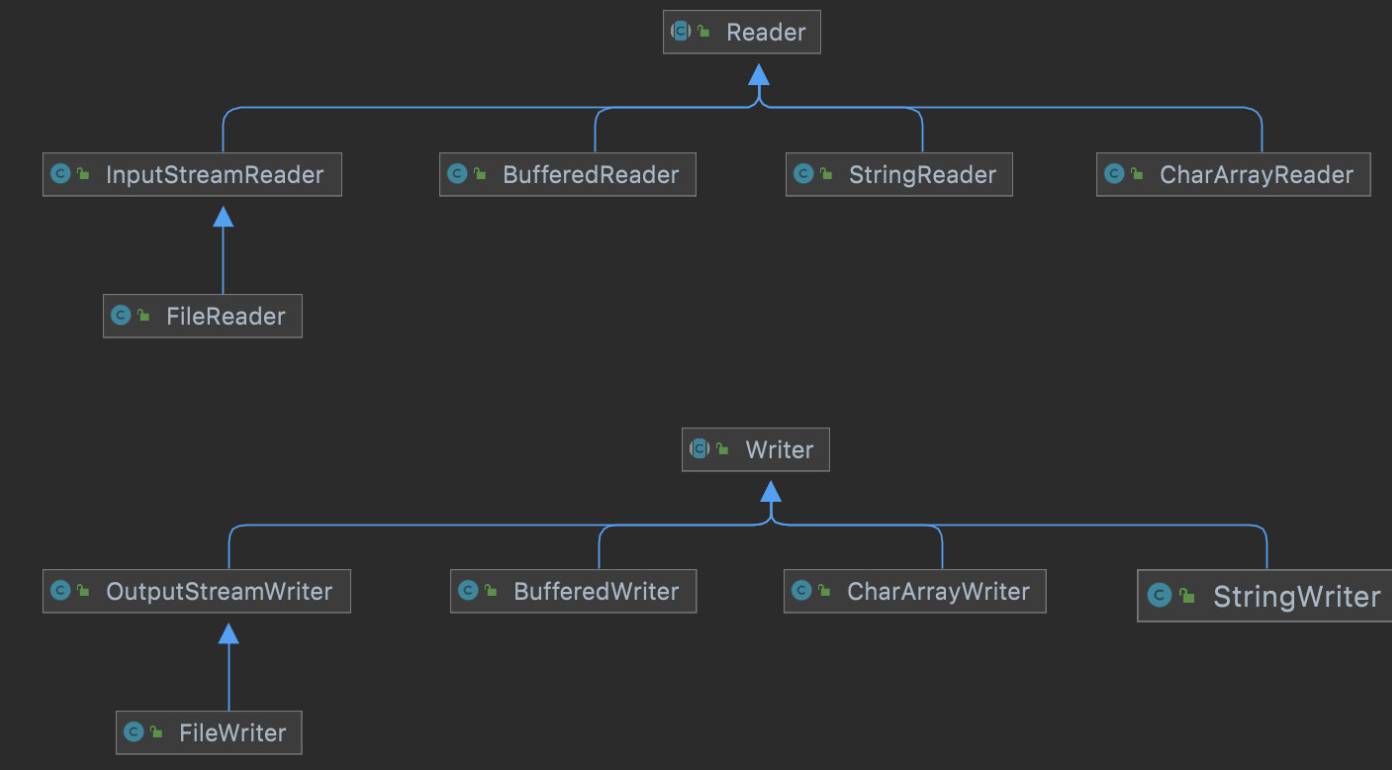
与面向字节的流相似,FileXXX和CharArrayXXX也是指明了数据的来源;用于改变流行为的装饰器类为BufferedXXX,但是却没有继承自FilterXXX(该类是个抽象类且没有子类,只用于占位)。InputStreamReader和OutputStreamWriter是适配器,可以接收一个字节流转为字符流。
BufferedInputStream详解
在读取文件的时候习惯性的会在FileInputStream之外再套一层BufferedInputStream用于提升性能,但是BufferedInputStream究竟是如何提升性能的呢?
先看他们的共同基类InputStream,在该类中关于数据读取的有三个方法
public abstract int read();
public int read(byte b[]);
public int read(byte b[],int off,int len);
第一个方法是抽象方法,需要其子类去实现。第二个方法会调用第三个方法,而第三个方法在基类中的实现是重复调用read()方法把byte数组b填充满。
对于FileInputStream,其部分源码如下
private native int read0() throws IOException;
private native int readBytes(byte b[], int off, int len) throws IOException;
public int read() throws IOException {
return read0();
}
public int read(byte b[]) throws IOException {
return readBytes(b, 0, b.length);
}
public int read(byte b[], int off, int len) throws IOException {
return readBytes(b, off, len);
}
read0()和readBytes()这两个是本地方法,与底层操作系统直接交互。read0()是一个byte一个byte的读取,而readBytes()则是将内容一次性读出到缓存byte b[]中,避免了频繁IO操作。
再看下BufferedInputStream类的源码:
private static int DEFAULT_BUFFER_SIZE = 8192; // 默认的缓冲字节数组长度
private static int MAX_BUFFER_SIZE = Integer.MAX_VALUE - 8; // 缓冲字节数据的最大长度
protected volatile byte buf[]; // 缓冲字节数组
protected int count; // 缓冲字节数组中已缓冲的数据长度,他应该小于等于buf.length
protected int pos; // 指的是一个读取数据的位置(应该从缓冲字节数组的哪个位置读取数据了)
/**
* 构造方法,传入被包装的终端流(对应我们例子中的就是FileInputStream实例)
*/
public BufferedInputStream(InputStream in) {
this(in, DEFAULT_BUFFER_SIZE); // 调用下面的构造方法,传入默认的缓冲数组长度
}
/**
* 构造方法,传入被包装的终端流以及缓冲数组的长度,最后就会按照给定长度初始化缓冲数组。
*/
public BufferedInputStream(InputStream in, int size) {
super(in);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
/**
* 获取被包装的终端流
*/
private InputStream getInIfOpen() throws IOException {
InputStream input = in;
if (input == null)
throw new IOException("Stream closed");
return input;
}
/**
* 获取缓冲字节数组
*/
private byte[] getBufIfOpen() throws IOException {
byte[] buffer = buf;
if (buffer == null)
throw new IOException("Stream closed");
return buffer;
}
/**
* 从缓冲区读取数据。
* 首先你要知道read方法是一个一个字节的读。当缓冲区为空的时候,就先把缓冲区填满(也可能一次填不满,假设你想要读100字节,但受限于内核以及网络通信等各种配置参数,可能一次返回的不足100字节),然后一个一个的从缓冲区读。缓冲区读完了之后,需要 再接着填 或者 清空缓冲区再重新填,然后再一个一个的从缓冲区读。这其中的接着填 和 清空重新填 的动作里,pos 和 count就两个变量全程参与了。
*/
public synchronized int read() throws IOException {
/*
pos 和 count都是 BufferedInputStream对象的实例属性。初始值都是0.
pos的作用就是标识要从缓冲的byte数组中的哪个位置读取下一个字节,每次成功读取一个,pos都要加1。
count的作用就是标识缓冲区有多少数据,缓冲区默认长度8192,但如果输入流只有100个字节,那么count就是100。
1、如果是第一次读,那么pos=0,count=0,缓冲区长度8192,假设读取回来100个字节,那么pos还是0,count=0 + 100 = 100。
2、这之后的100次read()调用,都从buf数组直接返回。然后pos = 100 了。
3、这时候 pos >= count了,因为缓冲的都读完了,所以要接着读数据然后往缓冲区填(fill),假设又读取回来500个字节,那么pos还是100,count= 100 + 500 = 600。
4、这之后的500次read()调用,都从buf数组直接返回。以此类推。
5、当count= buf.length的时候,再fill的时候,pos会从0开始,count = 0 + 读回来的字节数。
所以一旦pos >= count 就说明要么缓冲区还没有数据,要么缓冲区的数据都已经都读完了,总之需要重新填数据了(在后面接着填、或者清空从头填)。
*/
if (pos >= count) {
fill(); // 重点是这个方法,填充数据,下面有单独解析
if (pos >= count) // 如果执行了fill填充数据方法之后,pos还大于等于count,就说没有读取到数据,所以可以直接返回-1,表示已经读完了。
return -1;
}
// 走到这一步,就说缓冲区里有未读取的数据,那么从pos位置读一个字节返回,然后pos加1,下次从pos加1的位置接着读一个字节
return getBufIfOpen()[pos++] & 0xff;
}
/**
* 往缓冲区填充数据。
* 数据从哪来?从终端流读取而来。
*/
private void fill() throws IOException {
byte[] buffer = getBufIfOpen(); // 获取缓冲区字节数组(构造方法里已经初始化过),默认长度8192
// 省略了很多代码
...
count = pos;
// 重点是这一行代码,首先会通过getInIfOpen方法获取到被自己包装的终端流,对应我们例子中的也就是FileInputStream,然后调用FileInputStream的read(byte b[], int off, int len) 方法,读取出(buffer.length - pos)长度个数据,填充到buffer数组中(也就是把数据填充到缓冲区数组buf中的pos位置后面)
int n = getInIfOpen().read(buffer, pos, buffer.length - pos);
if (n > 0)
count = n + pos; // 如果n大于0,说明读取到了数据(但不一定就正好是buffer.length - pos个,可能不足这些个,但是没关系,总之数组能装下,然后更新数据的长度也就是count的值为pos+n)
// 如果n小于等于0,说明没读取到数据,以为上面设置了count = pos,所有从这个方法返回到上层方法后,还有if (pos >= count)的判断,这个判断后面就会直接return -1了。
}
/**
* 读取字节流到byte[] b中,如果需要,最多从输入流中调用一次内置流的read(byte[] b, int off, int len)方法
* 如果内置buffer有有效内容则读出,否则:
* 调用内置流read(byte[] b, int off, int len)方法 或 先读到内置buffer,然后把内容拷贝到byte[] b中
*/
private int read1(byte[] b, int off, int len) throws IOException {
int avail = count - pos;
// 内置buffer没有有效信息
if (avail <= 0) {
// 如果所需要的长度大于内置buffer的长度,则不拷贝,直接将内容读取到byte[] b中
if (len >= getBufIfOpen().length && markpos < 0) {
return getInIfOpen().read(b, off, len);
}
// 填充内置buffer
fill();
avail = count - pos;
if (avail <= 0) return -1;
}
int cnt = (avail < len) ? avail : len;
// 将内置buffer内容拷贝到byte[] b 中
System.arraycopy(getBufIfOpen(), pos, b, off, cnt);
pos += cnt;
return cnt;
}
/**
* 该方法会反复调用私有方法read1, 直至:
* 1. 指定长度的字节已经被读取
* 2. 内置的流返回-1,指示流已经无有效内容
* 3. 内置留的avaliable()方法返回0
*/
public synchronized int read(byte b[], int off, int len)
throws IOException
{
getBufIfOpen(); // Check for closed stream
if ((off | len | (off + len) | (b.length - (off + len))) < 0) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;
}
int n = 0;
for (;;) {
int nread = read1(b, off + n, len - n);
if (nread <= 0)
return (n == 0) ? nread : n;
n += nread;
if (n >= len)
return n;
// if not closed but no bytes available, return
InputStream input = in;
if (input != null && input.available() <= 0)
return n;
}
}
可见BufferedInputStream实际上是自己维护了一个buffer,对于read()方法从buffer中读取而不是调用流的read()方法避免频繁的IO;对于read(byte[] b, int off, int len)方法,则是根据情况从buffer中读取或者直接调用内置流的read(byte[] b, int off, int len)方法。
总而言之,BufferedInputStream通过维护一个buffer避免了频繁调用内置流的read()方法。