1. 现象
在完成DataTalk推送队列化改造后,为了测试全局限流措施的有效性,设置信号量为20,使用python脚本在同一时间触发BeaconJob任务触发接口40次,模拟高峰时期推送任务的情况,期望得到的结果是推送任务分2批完成。
经过观察结果符合预期,但是发现推送任务都显示推送失败。如果不经过BeaconJob触发,而是在DT界面点击立即推送触发则可以可以正常推送发出。
通过DT立即推送触发推送任务没有走推送队列化的逻辑,因此怀疑还是队列化改造把那里改出了问题。
看了下后台日志,发现果然有错误的log日志,如下图所示:
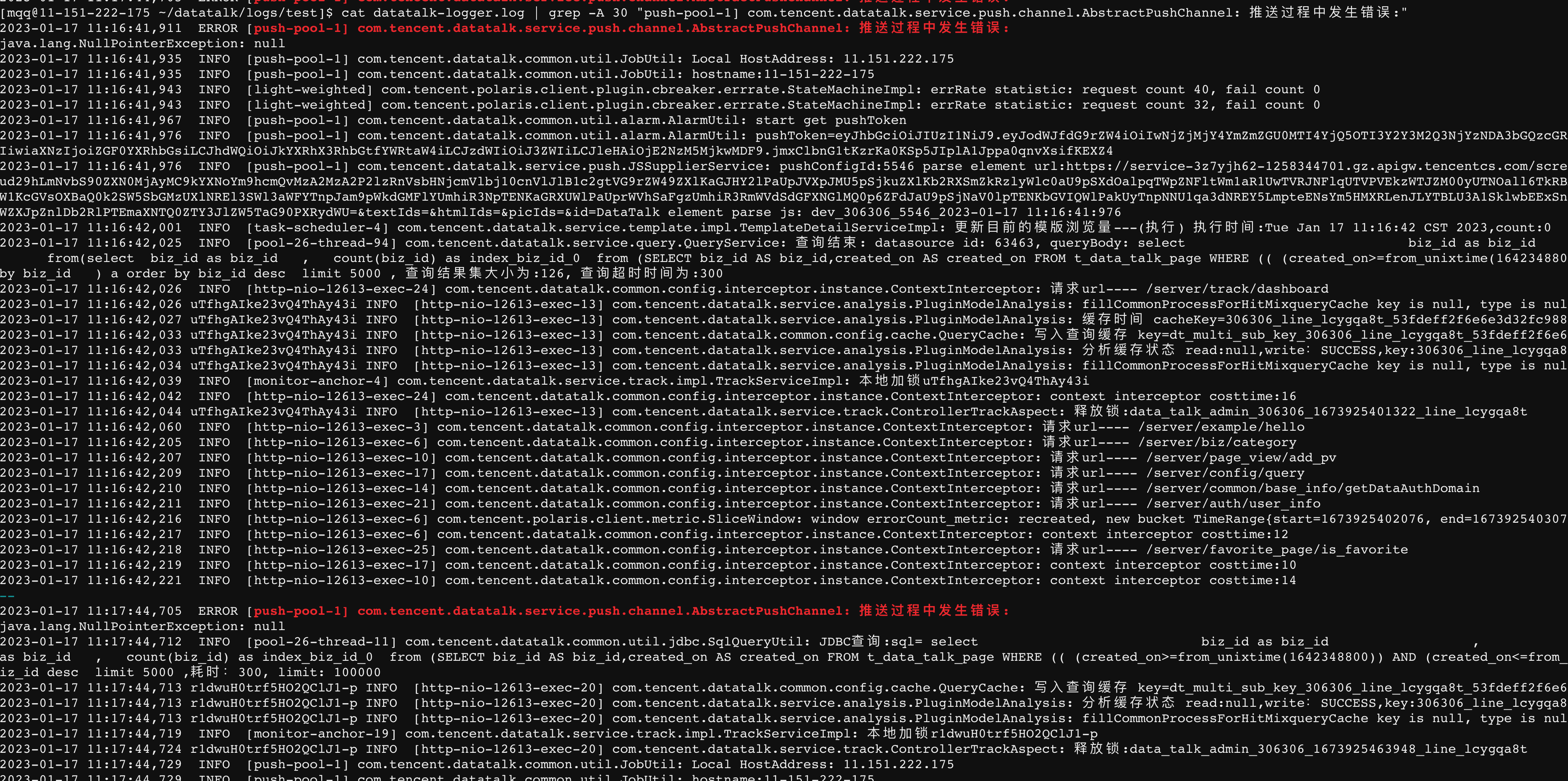
但是发现错误日志中没有堆栈信息。
根据log位置可以判断出错误信息抛出位置为:
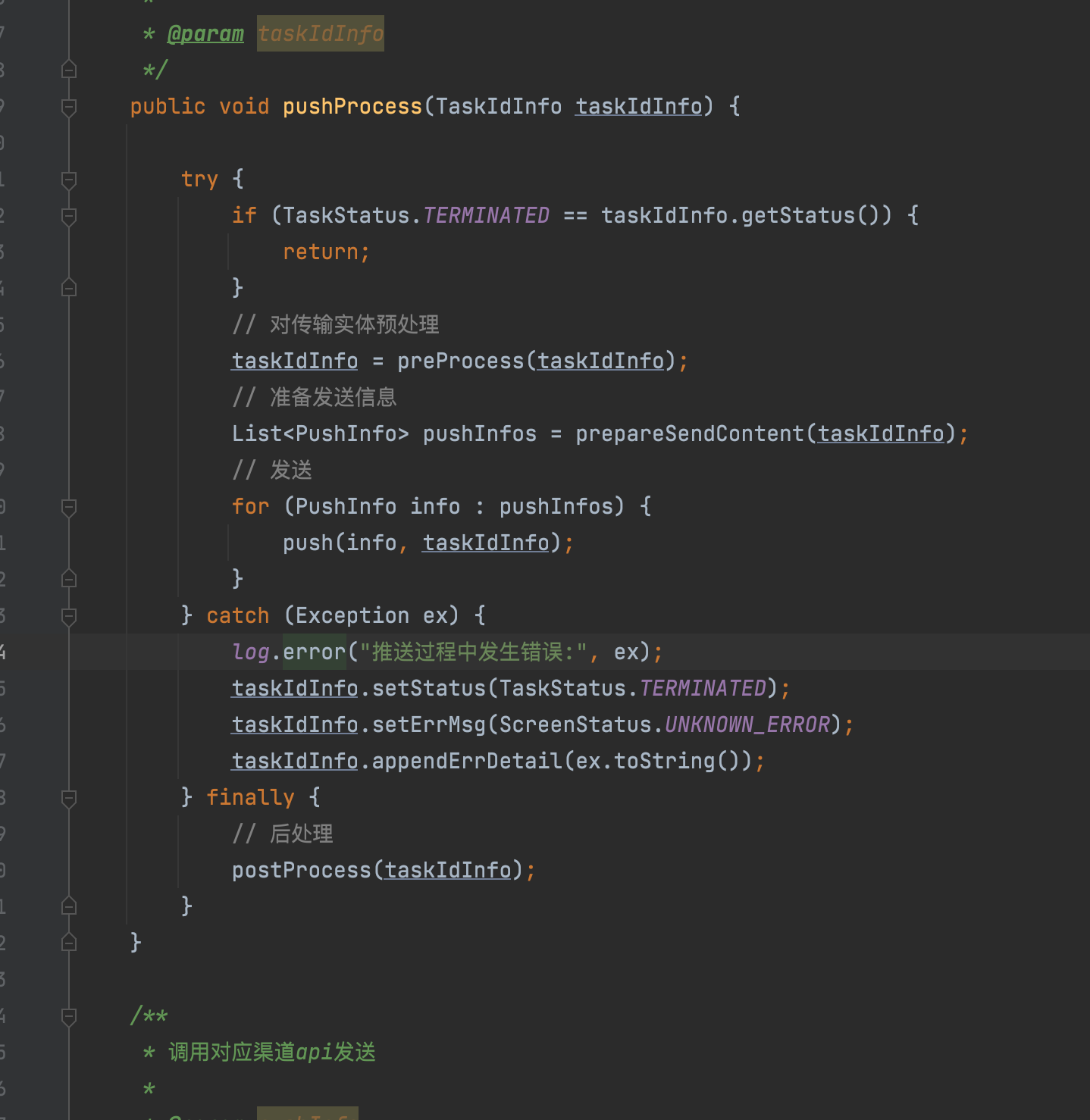
为了进一步确认,分别在preProcess方法,prepareSendContent方法以及push方法里使用try-catch进行包裹,然后再次触发推送任务,结果如下图所示
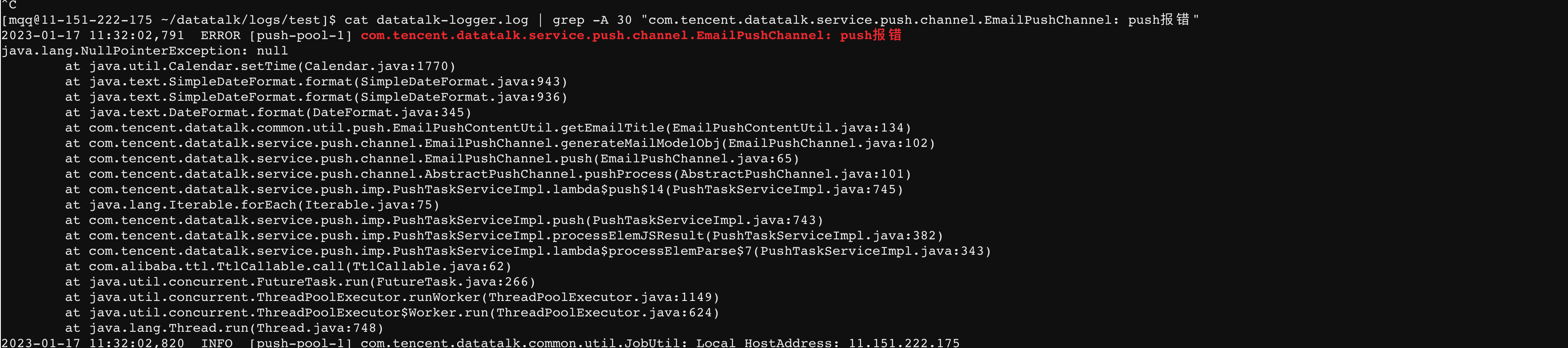
可见异常的堆栈信息被成功打印出来。根据该堆栈信息,也成功定位到了问题,并做出了修正。
但是为什么在内层使用try-catch可以把异常的堆栈信息成功捕获,而在外层则不行?Exception如果在内层没有被捕获,会一直保持原样往上抛出,这样的解释显然不合理,于是在网上搜索了相关资料得到了答案。
2. JIT即时编译
Java程序在运行初期是通过解释器来执行,当发现某块代码运行特别频繁,就会将之判定为热点代码(Hot Spot Code), 虚拟机会将这部分代码编译成本地机器码,并对这些代码进行优化。这件事就是即时编译(Just In Time, JIT)优化, 做这件事的就是即时编译器。
2.1 解释器与编译器
目前主流虚拟机都采用解释器、编译器并存的架构。
解释器:程序执行初期,解释器执行的方式可以省去编译过程,节省时间
编译器:在渡过初期后,编译器把更多的代码编译成本地代码,提升执行效率,以空间换时间
因为编译器存在过度优化,基于假设优化等可能失败的优化结果,通过逆优化(Deoptimization)的方式,将程序的执行主动权从编译器交给解释器执行。可以把解释器看成是一个保守派,编译器是一个激进派,在JVM执行体系里,两者相辅相成,互相配合。
2.2 编译器种类
一般虚拟机都内置了两个或三个即时编译器,历史比较久远的C1, C2, 以及在JDK10才出现的Graal
C1:客户端编译器(Client Complier),执行时间较短,启动程序的时间较快。在一些物联网小型设备上可指定这种编译器,通过-client参数强制指定
C2:服务端编译器(Server Complier),执行时间较长,启动时间较长但可编译高度优化的代码,峰值性能更高。可通过-server参数强制指定
Graal:是一个实验性质的即时编译器,其最大的特点是该编译器用Java语言编写,更加模块化,也更容易开发与维护。充分预热后Java代码编译成二进制码后其执行性能并不亚于由C++编写的C2。可以通过参数 -XX:+UnlockExperimentalVMOptions -XX:+UseJVMCICompiler 启用,并替换 C2
2.3 分层编译优化
虽然可以通过-Xint参数强制虚拟机处于"解释模式"此时编译器不工作,可以通过-Xcomp参数强制虚拟机处于"编译模式"此时解释器不工作,可以通过-client参数使C2不工作,也可以通过-server参数使C1不工作,但是并不推荐这样做,因为有分层编译优化这一特性。
编译器在编译代码的时候会占用程序运行时间,优化程度越高的代码编译时间会越长,甚至会需要解释器负责收集程序运行监控信息提供给编译器来编译优化程度更高的代码。所以为了在更短的时间内编译优化程度更高的代码,需要编译器之间的配合,也就是所谓的分层编译优化。一共有五层,分别是:
纯解释执行,解释器不开启收集程序运行监控信息
使用C1编译器进行简单可靠的优化,解释器不开启收集程序运行监控信息
仍然使用C1编译器优化,但是会针对方法调用次数和回边次数(循环代码调用次数)相关的统计
仍然使用C1编译器优化,统计信息才上一层的基础上会加上分支跳转、虚方法调用等全部统计信息,解释器火力全开
使用C2编译器优化,相比C1,C2会开启更多耗时更长的优化,还会根据解释器提供的程序运行信息进行一些更为激进的优化
在开启编译优化后,热点代码可能会被重复编译,C1编译器编译得更快,C2编译器编译质量更高,第0层模式解释器执行的时候也不用收集监控信息,第4层模式C2在进行耗时较长的编译较为忙碌时候,C1也能为C2承担一部分编译工作,交互关系如下图:
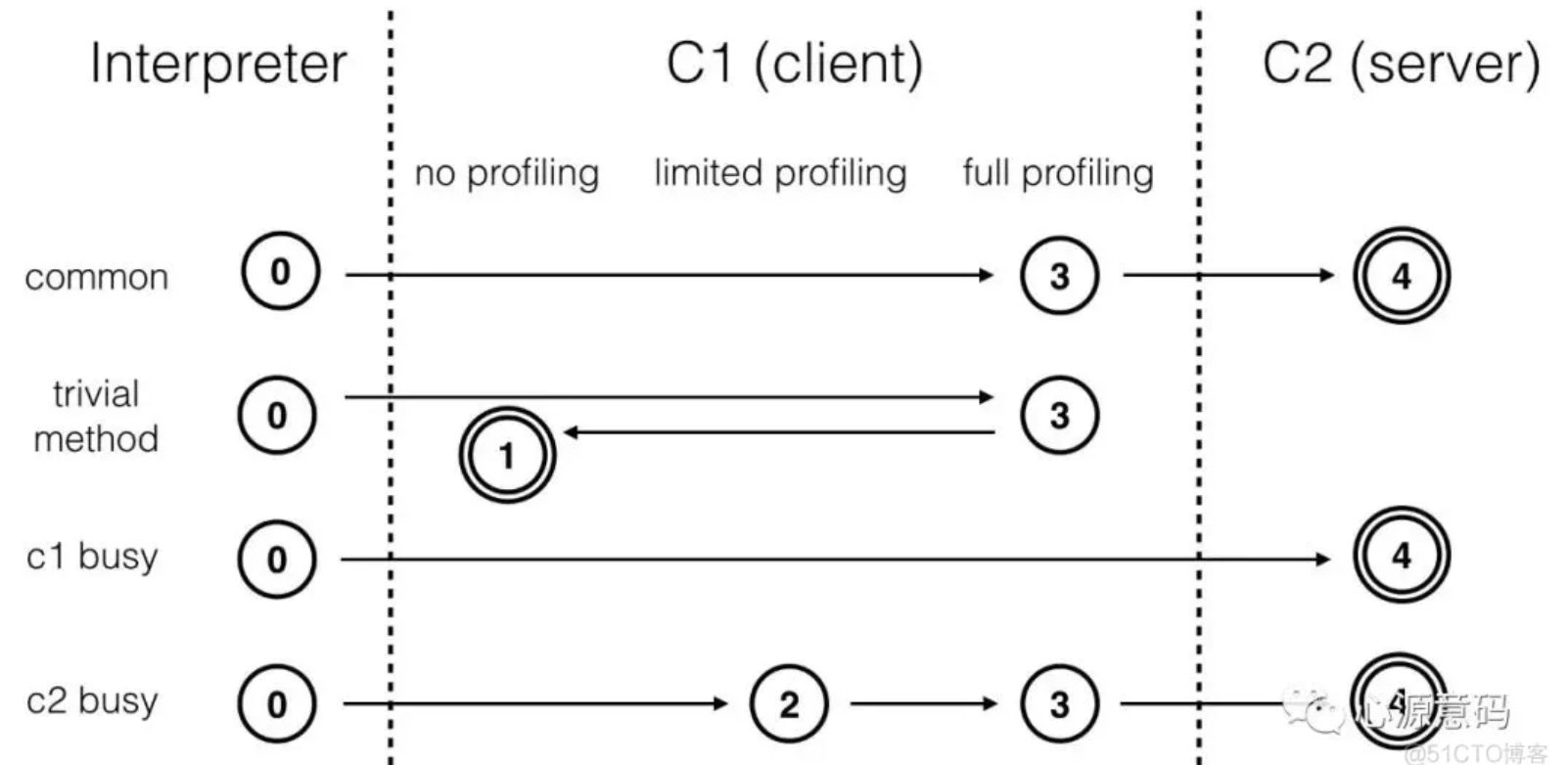
- common是针对大部分代码的编译情况,trival method针对执行次数较少的代码
- trival method很少被执行所以没有被C2编译的必要,通过第4层模式的优化就足够了
- 在C1忙碌的时候,会直接由C2编译;C2忙碌的时候,在C1编译的路径也会更长
2.4 编译触发条件
上面提到即使编译是针对热点代码进行编译优化,那么什么是热点代码?
- 被多次调用的方法
- 被多次执行的循环代码体
这里的多次如何知道具体有多少次?有两种方法可以知道
- 基于采样的热点探测(Sample Based Hot Spot Code Detection): 虚拟机周期性地检查各个线程的调用栈顶,如果发现某个方法经常出现在栈顶,那么这个方法就是热点方法,这种方法简单高效但是精确度不高
- 基于计数器的热点探测(Counter Based Hot Spot Code Dection): 虚拟机为每个方法建立计数器,计数器超过一定阈值就是热点方法
目前HotSpot虚拟机使用的是第二种方法,虚拟机为每个方法都准备了两类计数器,方法调用计数器以及回边计数器(回边的意思是在循环的末尾边界往回跳转,可以理解为循环代码的一次执行),而异常堆栈丢失就是JIT优化的一个案例。
在ORACLE官方文档中有这样一段描述
The compiler in the server VM now provides correct stack backtraces for all “cold” built-in exceptions. For performance purposes, when such an exception is thrown a few times, the method may be recompiled. After recompilation, the compiler may choose a faster tactic using preallocated exceptions that do not provide a stack trace. To disable completely the use of preallocated exceptions, use this new flag: -XX:-OmitStackTraceInFastThrow.
即对于经常反复抛出的内置异常,JVM会进行重编译,通过不提供堆栈信息来提高抛出速度。
问题解决办法
正如官方文档里的描述,可以使用-XX:OmitStackTraceFastThrow来禁用fast throw。
在我进行推送压测的时候,一次性触发了40次推送任务,这40次推送任务因为代码逻辑,都会在相同的位置报错,因此触发了JIT优化,在我使用tail -f命令看后台日志的时候是从后往前看的,因此我看到的是被优化后没有堆栈信息的报错。
当我对内层方法进行try-catch后,触发了一次推送任务,并马上查看了后台日志,此时异常报错并没有被JIT优化,自然就看到了异常的堆栈信息。