本文总结自以下两篇博文,https://blog.csdn.net/weixin_44460333/article/details/86770169,https://my.oschina.net/pingpangkuangmo/blog/817973,修改了一些typo,并添加了一部分自己的理解,非常感谢两位博主的精彩总结以及无私奉献!
众所周知,HashMap是线程不安全的,当并发操作HashMap会产生诸多问题,甚至在JDK1.7中,多线程对HashMap进行扩容时,会形成环形链表。ConcurrentHashMap是HashMap的多线程安全版,其在JDK1.7之后发生了很多变化,在此我们进行一些对比。
1. ConCurrentHashMap在JDK1.7中的设计
ConcurrentHashMap是线程安全,通过分段锁的方式提高了并发度。分段是一开始就确定的了,后期不能再进行扩容的。通过分段锁,其支持N个Segment这么多次数的并发。
其中的段Segment继承了重入锁ReentrantLock,有了锁的功能,同时含有类似HashMap中的数组加链表结构(这里没有使用红黑树)
虽然Segment的个数是不能扩容的,但是单个Segment里面的数组是可以扩容的。其底层结构如下图所示:
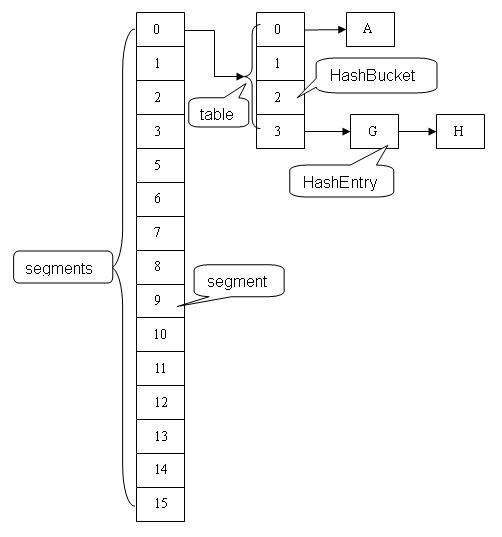
1.1 整体概览
Conccurent核心成员变量:
1 /**
2 * Segment 数组,存放数据时首先需要定位到具体的 Segment 中。
3 */
4 final Segment<K,V>[] segments;
5
6 transient Set<K> keySet;
7 transient Set<Map.Entry<K,V>> entrySet;
Segment是ConcurrentHashMap的一个内部类,主要组成如下:
1 static final class Segment<K,V> extends ReentrantLock implements Serializable {
2
3 private static final long serialVersionUID = 2249069246763182397L;
4
5 // Segment中有一个table,等同于HashMap中的table
6 transient volatile HashEntry<K,V>[] table;
7
8 transient int count;
9
10 transient int modCount;
11
12 transient int threshold;
13
14 final float loadFactor;
15
16 }
再看一下HashEntry的组成:
static final class HashEntry<K,V>{
final int hash;
final K key;
volatile V value; //重点!使用volatile保证了value变量在内存的可见性
volatile HashEntry<K,V> next; //重点!保证了链表的指针在内存的可见性
HashEntry(int hash,K key, V value, HashEntry<K,V> next){
this.hash=hash;
this.key=key;
this.value=value;
this.next=next;
}
}
1.2 put过程
- 首先是通过 key 定位到 Segment,之后在对应的 Segment 中进行具体的 put。
- 在
1尝试获取锁,如果获取失败,则可定时有其他线程存在竞争,则利用scanAndLockForPut()自旋获取锁 - 在当前的Segment中的table中,通过key的hashCode定位到了HashEntry
- 遍历该HashEntry,如果不为空则判断传入的key和当前遍历的key是否相等,相等则覆盖,
2 - 为空则需要新建一个 HashEntry 并加入到 Segment 中,同时会先判断是否需要扩容,
3 - 释放锁
4
public V put(K key, V value) {
2 Segment<K,V> s;
3 if (value == null)
4 throw new NullPointerException();
5 int hash = hash(key);
6 int j = (hash >>> segmentShift) & segmentMask;
7 if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
8 (segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
9 s = ensureSegment(j);
10 return s.put(key, hash, value, false); //根据定位到的Segment,调用Segment的put方法
11 }
scanAndLockForPut()函数,其实是通过自旋等待获取锁,如果指定次数未得到,则阻塞
1.3 扩容过程
扩容是在Segment的锁保护下进行扩容的,不需要关注并发问题。
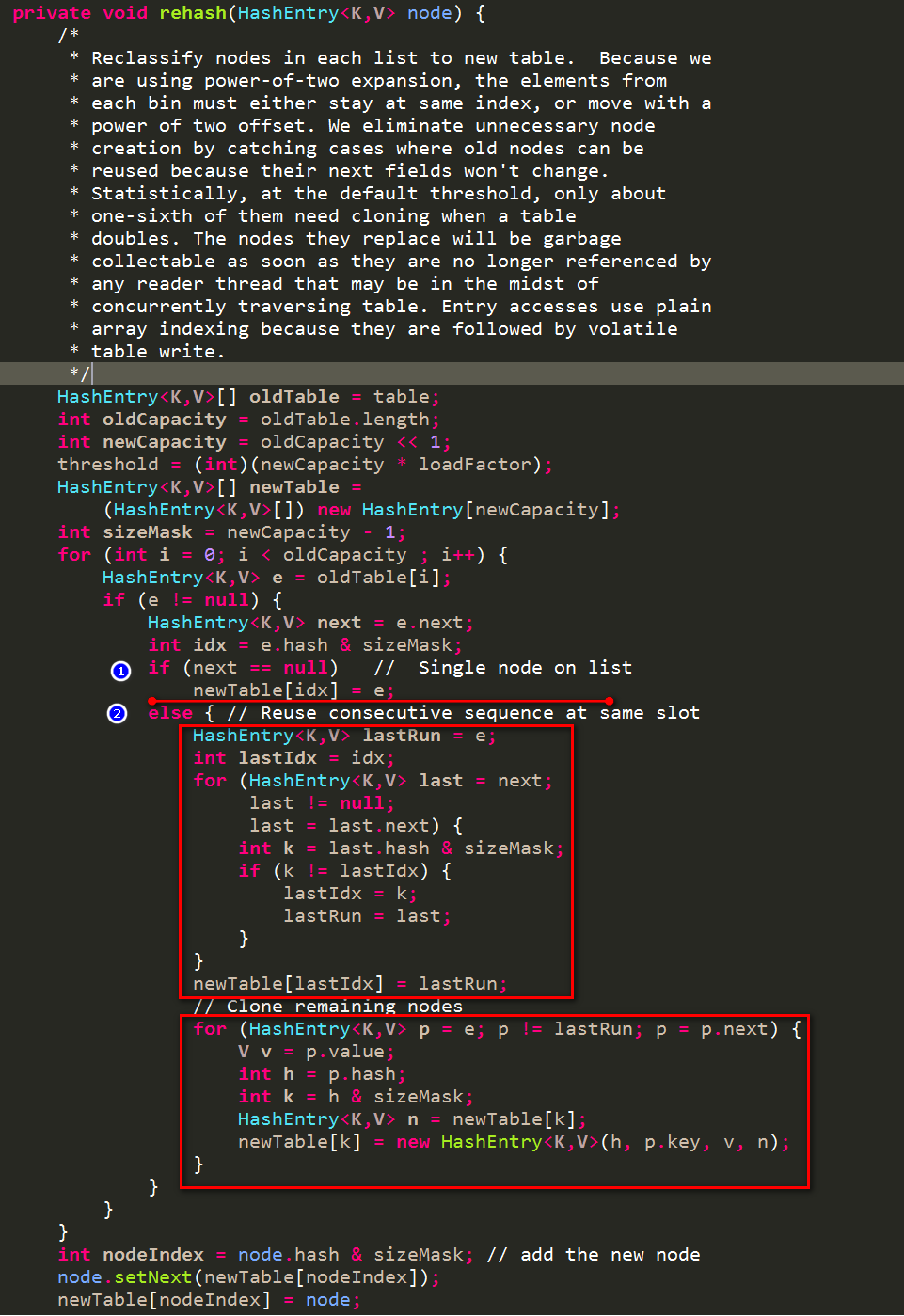
这里的重点就是:首先找到一个lastRun。因为扩容后需要reHash,这些结点可能会分配到不同的新桶中,但也会有一些节点在相同的桶中,为了减少移动操作,我们在原来某个桶的链条上从头到尾进行遍历,用lastRun来指明一个结点,自该节点之后的所有节点都在相同的桶中(也有可能很不幸,lastRun没有后续结点,但这不重要)
然后对开始到lastRun部分的元素,重新计算下设置到newTable中,每次都是将当前元素作为newTable的首元素,之前老的链表作为该首元素的next部分。(表头插入)
1.4 get过程
- 根据key计算出对应的Segment
- 再根据key计算出对应segment中数组的index
- 最终遍历上述index位置的链表,查找出对应的key的value
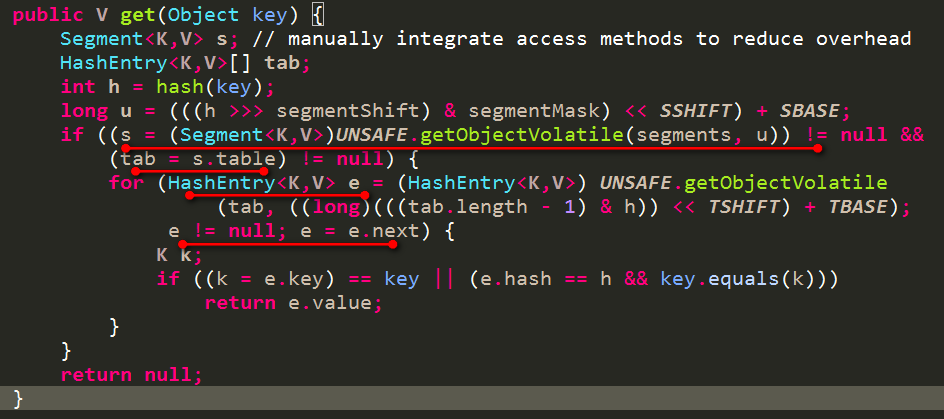
2. ConCurrentHashMap在JDK1.8中的设计
1.8的ConcurrentHashMap摒弃了1.7的segment设计,而是在1.8HashMap的基础上使用CAS + synchronized实现了线程安全。(也可以理解为将锁细化了,将锁加载每一个桶上)
数组可以扩容,链表可以转化为红黑树,其底层结构如下图所示:
摒弃了原来的Segment分段锁结果,并将存放数据的HashEntry改为了Node,但作用是相同的。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
在新版的ConcurrentHashMap中,有一个重要的参数sizeCtl,代表数组大小,但其还有其他的含义,后面再详细说到。
2.1 put操作
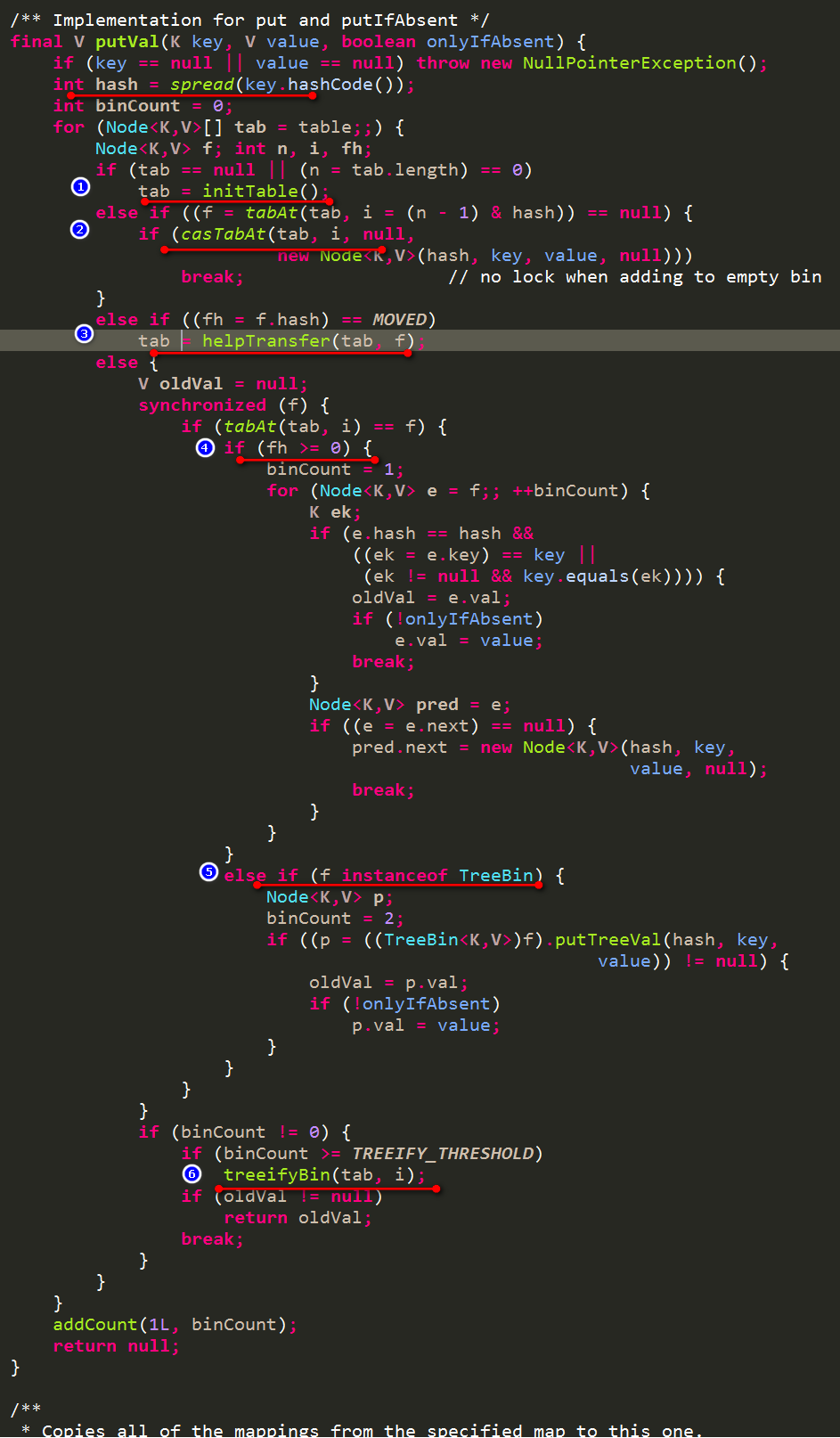
- 如果数组还未初始化,那么进行初始化,这里会通过一个CAS操作(compare and set 原子操作)将sizeCtl设置为-1,设置成功的,可以进行初始化操作
- 根据key的hash值找到对应的桶,如果桶中还没有元素,那么通过一个CAS操作来设置桶的第一个元素(Expected:Null,New Value:new Node…),失败的继续执行下面的逻辑即向桶中插入或更新
- 如果找到的桶存在,但是桶中第一个元素的hash值是-1,说明此时该桶正在进行迁移操作,这一块会在下面的扩容中详细谈及。
- 如果找到的桶存在,那么要么是链表结构要么是红黑树结构,此时需要获取该桶的锁,在锁定的情况下执行链表或者红黑树的插入或更新
- 如果桶中第一个元素的hash值大于0,说明是链表结构,则对链表插入或者更新
- 如果桶中的第一个元素类型是TreeBin,说明是红黑树结构,则按照红黑树的方式进行插入或者更新
- 在锁的保护下插入或者更新完毕后,如果是链表结构,需要判断链表中元素的数量是否超过8(默认),一旦超过就要考虑进行数组扩容或者是链表转红黑树
2.2 get操作
- 根据计算出来的 hashcode 寻址,如果就在桶上那么直接返回值。
- 如果是红黑树那就按照树的方式获取值。
- 就不满足那就按照链表的方式遍历获取值。
我们注意到,对ConcurrentHashMap的读操作没有用到锁,因此get的操作是弱一致性的,什么是弱一致性?弱一致性主要是为了提升效率,也是一致性和效率之间的一种权衡。对于get操作而言,其弱一致性导致的后果是get操作只能保证一定能看到已完成的put操作。同时,clear也是弱一致性的,更详细的解释详见这篇文章
3. 总结
在JDK1.7中,ConcurrentHashMap的设计框架是使用了分段锁的思想,在进行put中,都是使用lock()进行加锁;到了JDK1.8时代,取消了分段锁这一机制,取而代之的是CAS+synchronized操作,可见在JDK1.8之后,已经对synchronized进行了长足的优化。
对ConcurrentHashMap的读操作不需要加锁,而是使用volitale关键字保证了内存的一致性。